從人工判斷到狀態機設計: 用 Python 自動化半導體 EQC 抽樣規則
每月都需根據歷史資料重新判斷EQC抽樣策略,但資料分散、規則複雜,人工計算容易出錯且難以維持一致性。AS IS: 仰賴人工紀錄與計算 → NOW: 透過 Python 搭配 container 部署,自動完成計算並定時產出報告。
Photo by Maxence Pira on Unsplash

在半導體製造業中,如何根據歷史資料制定抽樣計畫,是品質管理的重要一環。
本文將分享一段使用 Python 與 Pandas,將這套原本依賴人工判斷的流程轉為可自動化的下一期抽樣計畫,並將問題思考方向從半導體品質判斷,轉換成「時間序列處理,滑動視窗與狀態機推導」的演算法設計問題。
所有資料皆為模擬,邏輯來自實務經驗,數字經過調整,不涉及任何機密資訊。
前言
EQC(Engineering Quality Control)電性品管是針對最終測試(FT)通過的產品進行抽樣驗證,目的在於確保測試程式的有效性,避免不良品流出。
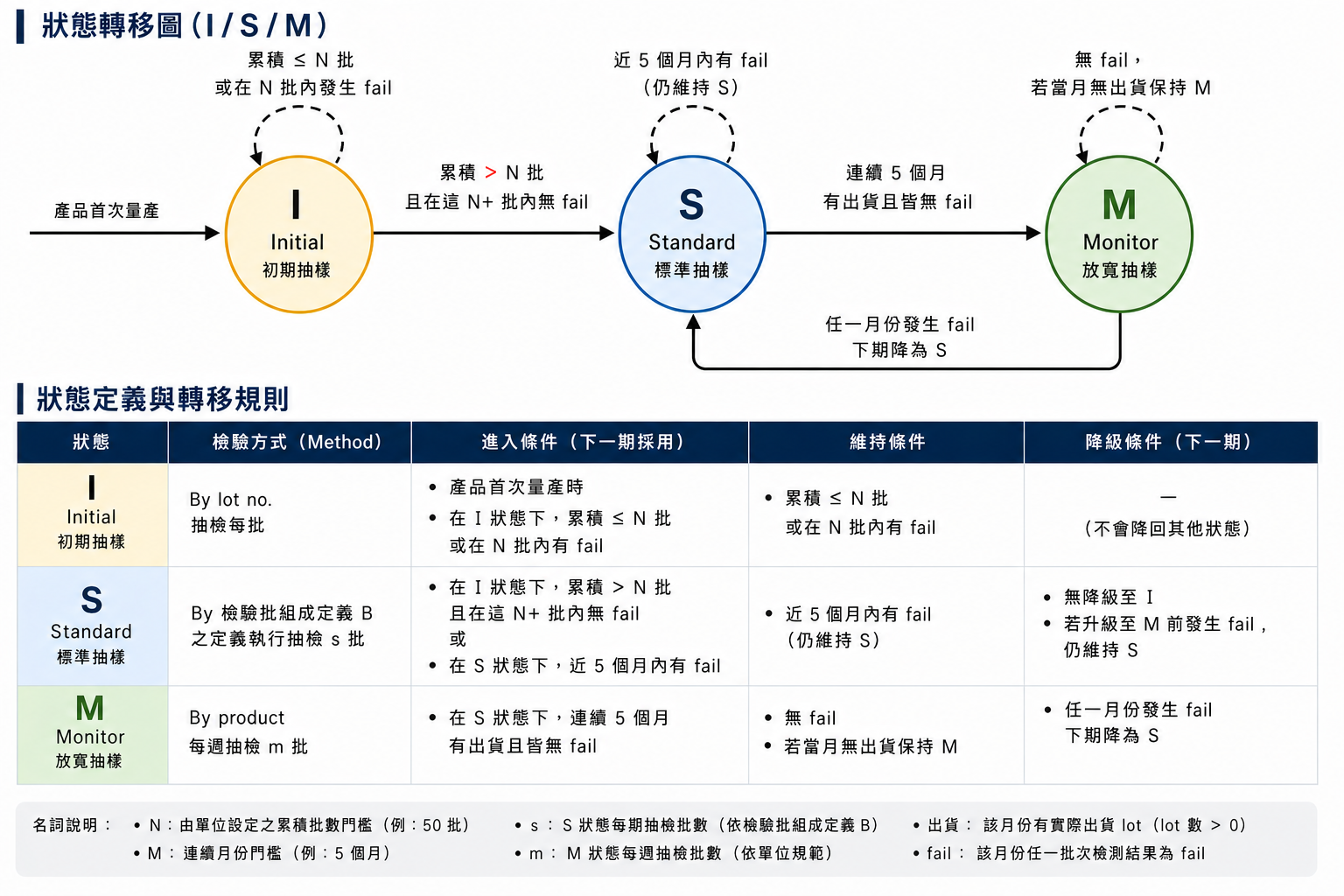
我們希望根據每個產品在不同代工廠的歷史抽樣結果,得到下一期應採用的抽樣策略。抽樣策略分為三種狀態,狀態重點在於轉移規則:
I:初期抽樣(少於或等於 N 批 lot),例如 N=50,此處N是所有相同產品的lot批數加總,包含所有供應商。S:標準抽樣,S, M的標準由不同供應商分開計算。M:放寬抽樣(連續 M 期無失敗且 lot 數充足),例如 M=5。
當Lot 出貨未滿N批時,狀態是I (initial),例如 N=50。
前N批檢查都沒有fail時,就會晉級到狀態 S (standard),此產品連續M個月都有出貨且連續M個月都沒有檢查到fail,狀態會晉級到 M (moniter)。
如果M狀態出現fail,就會退回到S,重複 產品連續5個月都有出貨,且連續5個月都沒有檢查到fail” 晉級到M,否則則保持S。
問題
在每月22號時,會根據上個月的資料 (上個月19號到這個月18號) 的資料決定下個月的檢測標準狀態。
在資料規模上,此問題同時包含多供應商、多產品與長時間序列:
-
約 15 個供應商,涵蓋 DRAM 與 Flash 產品
-
約 100 個產品,投產時間不一致,資料跨度可達 10 年
-
同一批 lot 在不同月份可能重複檢測,也可能送往不同供應商,需依供應商與 fail 狀態去除重覆
-
整體計算與報告產出需在 30 秒內完成
思路
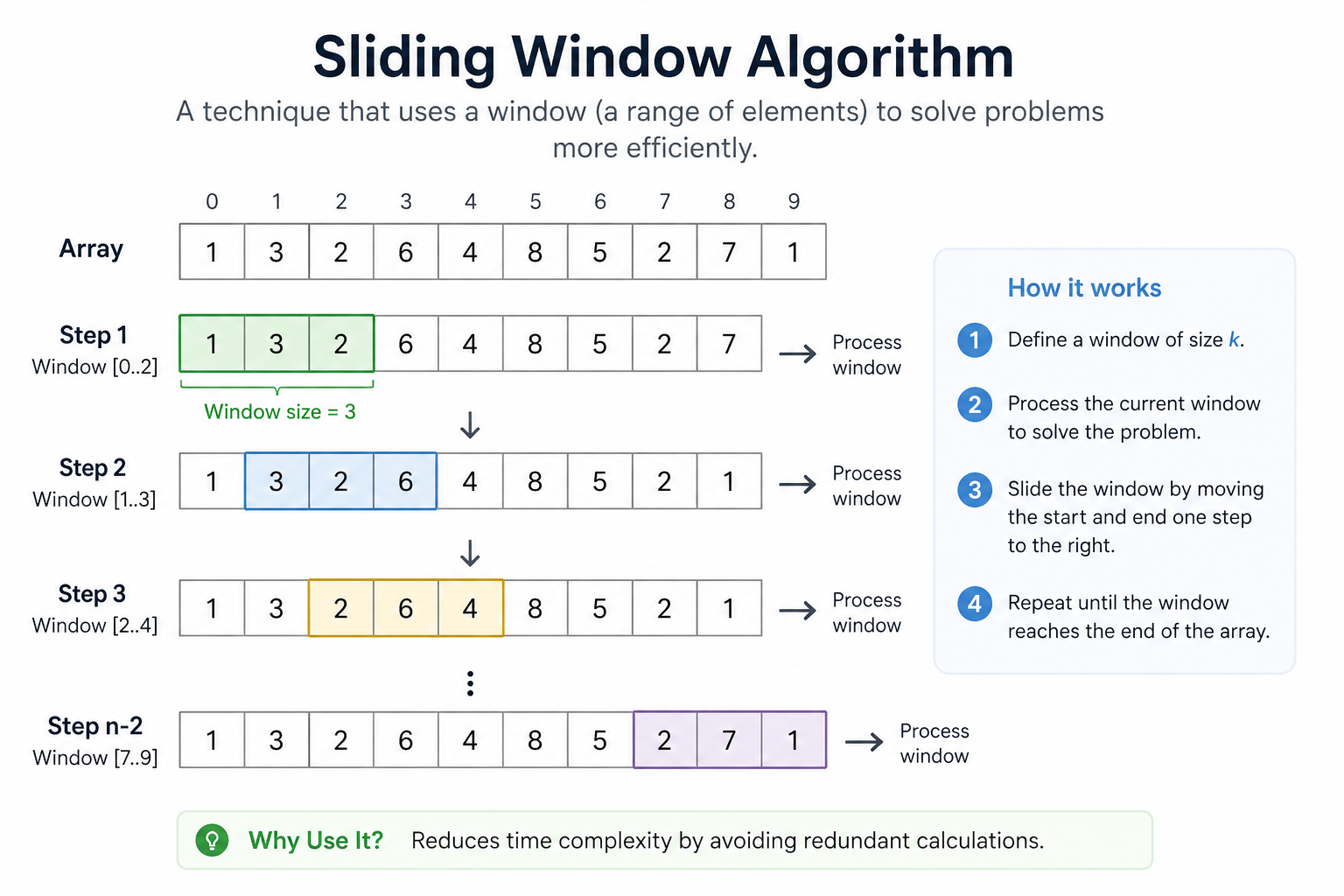
一開始接到這個project,我直覺想到可以用滑動視窗(sliding window)的方式來判斷抽樣策略。
舉例來說,如果某產品在最近M期的狀態都是 S,且 fail 都是 0,每月都有出貨(lot 數 > 0),那就可以晉級為 M。
以下簡單繪製示意狀態。
| Month | Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Lot | 10 | 20 | 15 | 10 | 12 | 10 | 8 | 9 | 7 | 6 | 5 |
| CumLot | 10 | 30 | 45 | 55 | 67 | 77 | 85 | 94 | 101 | 107 | 112 |
| Fail (t) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| NextState (t+1) | I | I | I | S | S | S | S | S | M | S | S |
但實際情況比這更複雜:
1. 狀態依賴歷史(Stateful)
抽樣策略並非只取決於當期資料,而是與過去累積 lot、fail 紀錄與歷史狀態相關。
- 一旦產品晉級到
M,就算某月沒出貨,也要維持M,除非該月有 fail 才會退回S。 - 要從
I晉級到S,必須累積 N 批出貨且都沒有 fail。如果其中有 fail,就繼續保持I,直到下一個「N 批無 fail」的區間。 S狀態下即使有 fail,也不會退回I。
此外,每個產品的投產時間不同,時間間隔也不一致,因此需要補齊每個產品的完整月份資料,才能正確判斷是否符合 S 或 M 的條件。
2. 多種條件混合(Mixed Constraints)
| 類型 | 對應規則 |
|---|---|
| 累積lot(Cumulative) | I → S |
| 連續月份(Consecutive) | S → M |
| fail事件觸發(Event-driven) | M → S |
這三種條件屬於不同維度,無法用單一統計或單一 window 處理。
3. 時間序列不完整(Irregular Time Series)
此外,每個產品的投產時間不同,時間間隔也不一致,因此需要補齊每個產品的完整月份資料,才能正確判斷是否符合 S 或 M 的條件。
4. 資料需全量重算(Full Re-computation)
最後,由於歷史資料可能會被修正(例如誤判fail),不能確定往回修正多久前的紀錄,因此,不能只看最近M期的資料,而是每次都要重新計算整段歷史,確保判斷結果是動態且準確的。
因此,這個問題表面是抽樣計畫計算、與單純的統計彙總,但核心是一個需要記憶狀態、並判斷的問題。
每個產品與供應商組合在不同月份會根據過去狀態、fail 紀錄、lot 數量,決定下一期要採用 I, S 或 M。也就是說,當月的抽樣計畫,取決於過去的歷史狀態累積。
演算法邏輯對應
整體流程為:
原始 lot 資料 → 會計月轉換 → lot 去重彙總 → 補齊連續月份 → 逐月推導 I / S / M 狀態 → 預測下一期抽樣計畫
- 把日期切到「19~18」的對帳月,上月19號至當月18號為當月資料 ex. 4月資料來源為3/19~4/18
- 把重複lot去掉,同供應商重複檢測不重覆計數;跨供應商視為不同檢測
- 彙整到月表,製作dataframe,並補齊每個
product + subcon的完整月份序列 - 計算累積 lot (
CumLot),作為 I → S 判斷依據 - 逐月跑狀態 (I / S / M),以當期資料推導下一期狀態。也就是:逐月跑狀態 I / S / M,其中第 t 期狀態會根據前期狀態、最近 3 期紀錄,以及第 t 期是否發生 fail 共同決定。
| 演算法類型 | 解決的問題 | 對應函式 |
|---|---|---|
| 會計月轉換 | 將日期切成 19~18 的計算月份 | add_cal_month() |
| 資料篩選 | 排除不納入計算的供應商與超出報表截止日的資料 | filter_valid_data() |
| lot 去重 | 將重複檢測紀錄整理成 lot-level 資料 | aggregate_lot_data() |
| 月表彙總 | 統計每個 product + subcon + month 的 lot 數與 fail 數 | summarize_monthly_lots() |
| 時間序列補齊 | 補齊每個 product + subcon 的連續月份 | build_monthly_sequence() |
| 初始狀態判斷 | 根據累積 lot 數建立初始 I / S 狀態 | assign_initial_plan() |
| 狀態機推導 | 逐月推導 I / S / M 狀態 | mark_ism_status() / apply_ism_status() |
| 下一期預測 | 取最新狀態與最近 3 期資料推導下期計畫 | predict_next_plan() |
程式碼實作
起手式
| 類型 | 說明 |
|---|---|
| regexp 規則分類 | 使用 regexp按照規則分類產品 |
| 資料流程設計 | 將整個分析流程模組化 |
日期轉換:建立會計月
因為把上月19號至當月18號為當月資料 ,有會計月的概念,因此需要先處理日期,將原始日期轉換成對應的 cal_month。
舉例來說:
- 3/19~4/18 的資料,會被歸到 4 月
- 4/19~5/18 的資料,會被歸到 5 月
第一步轉換日期,可以讓後續的 lot 統計、狀態推導與下期預測,都建立在一致的月報週期上。
當檢測日期大於當月 18 號時,代表這筆資料已經進入下一個月報週期,因此 cal_month 會往後推一個月;反之,則維持在當月。
透過這個轉換,原始檢測日期就會被整理成公司實際使用的月報月份,而不是一般日曆月份。
這裡, 我使用 is_next_month = data[date_col].dt.day > THRESHOLD_DAY 產生boolean值,可以在後續處理中,即使是大量的row,也能做快速判斷
THRESHOLD_DAY = 18
def add_cal_month(data, date_col="date_col"):
"""
Convert raw inspection dates into accounting months based on a 19–18 cycle.
Rules:
- Dates from the 1st to the 18th belong to the current month.
- Dates from the 19th onward belong to the next accounting month.
"""
data = data.copy()
data[date_col] = pd.to_datetime(data[date_col])
is_next_month = data[date_col].dt.day > THRESHOLD_DAY
data["cal_month"] = data[date_col].dt.to_period("M") + is_next_month.astype(int)
return data
篩選資料與 lot 去除重複彙總
完成會計月轉換後,下一步是把原始檢測紀錄整理成月表。
-
排除不需要納入計算的供應商
-
將重複檢測的 lot 去除重複,匯總成同一筆月資料
同一個 lot_id 如果在相同 product + subcon + cal_month 下重複檢測,會被視為同一批檢測資料;但如果是不同供應商,則會保留為不同檢測紀錄。
這裡的 fail_or_not 不是只拿來看次數,而是用來判斷該 lot 或該月是否曾經發生 fail;因此後續只要 fail_or_not > 0,就視為該月有 fail。
filter_valid_data() 負責先把不需要進入計算的資料排除,例如不納入計算的供應商,或超過本次報表截止日的資料。
aggregate_lot_data() 則是 lot 去重的核心。因為原始資料可能會出現同一批 lot 重複檢測的情況,所以這裡用 subcon_id + prod_no + lot_id + cal_month 作為key,將同一批檢測資料彙總成一筆。
這樣處理後, 資料會從原始檢測紀錄,轉換成每月 lot 檢測單位 ,後續才能進一步統計每個 product + subcon 在每個月的 lot 數與 fail 次數。
接下來,就可以計算I, S, M的狀態了。
def filter_valid_data(data, exclude_subcon, end_date):
"""
Filter valid inspection records before aggregation.
Rules:
- Exclude specific subcon suppliers.
- Keep only records within the reporting cutoff date.
"""
data = data.copy()
data["date_col"] = pd.to_datetime(data["date_col"])
filtered = data[
(data["date_col"] <= end_date)
& (~data["subcon_id"].isin(exclude_subcon))
].copy()
return filtered
def aggregate_lot_data(data):
"""
Aggregate raw inspection records into monthly lot-level data.
Rules:
- The same lot under the same subcon, product, and accounting month
is treated as one inspection unit.
- Fail counts are summed to preserve whether the lot has failed.
- The latest inspection date is kept as the representative date.
"""
lot_data = (
data
.groupby(["subcon_id", "prod_no", "lot_id", "cal_month"], as_index=False)
.agg({
"fail_or_not": "sum",
"rn": "sum",
"date_col": "max"
})
)
return lot_data
def summarize_monthly_lots(lot_data):
"""
Summarize lot-level data into monthly product-subcon records.
Output:
- lot_num: number of inspected lots in the month
- fail_or_not: total fail count in the month
"""
summary_data = (
lot_data
.groupby(["subcon_id", "prod_no", "cal_month"], as_index=False)
.agg({
"fail_or_not": "sum",
"lot_id": "count"
})
.rename(columns={"lot_id": "lot_num"})
)
return summary_data
補齊連續月份與累積 lot 數
完成 lot 彙總後,資料已經被整理成每個 product + subcon + cal_month 的月表。
但原始資料不一定每個月都有檢測紀錄。如果直接用現有資料推導狀態,會造成時間序列不連續,就會影響後續判斷。
因此這一步會先補齊每個 product + subcon 的完整月份序列,沒有檢測資料的月份則補上 lot_num = 0、fail_or_not = 0。
接著計算每個產品的累積 lot 數 cum_lot,作為初期檢測狀態 I 是否轉入標準檢測狀態 S 的判斷依據。
這段程式的關鍵是建立 skeleton。
skeleton 代表每個 product + subcon 都應該擁有完整的月份序列,即使某個月沒有檢測資料,也會被保留下來。
這樣做的原因是:I / S / M 狀態包含時間序列,如果中間缺月份,就無法正確判斷連續三期或上一期狀態。
接下來,再用 cum_lot 計算每個產品的累積 lot 數,作為後續判斷 I → S 的基礎。
cum_lot 使用Pandas 的 cumsum() ,它是 利用 Prefix Sum 演算法,在分組後的記憶體區塊中,利用指標偏移直接進行累加。這樣可以避開昂貴的迴圈,直接在 C 語言層級的連續記憶體上利用指標偏移(Pointer Offset)進行累加。
def build_monthly_sequence(summary_data):
"""
Build a continuous monthly sequence for each product-subcon pair.
Steps:
- Convert cal_month into monthly Period format.
- Create a complete month skeleton for each product-subcon pair.
- Fill missing months with zero lot count and zero fail count.
- Calculate cumulative lot count for each product.
"""
df = summary_data.copy()
df["cal_month"] = pd.PeriodIndex(df["cal_month"], freq="M")
keys = df[["prod_no", "subcon_id"]].drop_duplicates()
months = pd.DataFrame({
"cal_month": pd.period_range(
df["cal_month"].min(),
df["cal_month"].max(),
freq="M"
)
})
skeleton = (
keys.assign(_key=1)
.merge(months.assign(_key=1), on="_key")
.drop(columns="_key")
)
result = (
skeleton
.merge(df, on=["prod_no", "subcon_id", "cal_month"], how="left")
.fillna({"lot_num": 0, "fail_or_not": 0})
)
result["prod_subcon"] = result["prod_no"] + "_" + result["subcon_id"]
result = result.sort_values(["prod_no", "cal_month"]).reset_index(drop=True)
result["cum_lot"] = result.groupby("prod_no")["lot_num"].cumsum()
return result
💡 透過閱讀Source code可以發現,Pandas 的
cumsum函數實際上是一個 Dispatching 機制。它在 Python 裡只有進行參數校驗與numeric_only的預處理,隨即將計算任務下放到NDFrame核心
建立初始 I / S 狀態
如前述規則所述,當累積 lot 數超過N後(此處設N=50),產品會從 I進入 S ,是否能從 S 轉成 M,則要再根據連續月份是否都有檢測資料、是否沒有 fail,以及前期狀態來判斷。
INITIAL_LIMIT = 50
def assign_initial_plan(monthly_data):
"""
Assign the initial inspection plan based on cumulative lot count.
Rules:
- I: cumulative lot count is within the initial inspection limit.
- S: cumulative lot count exceeds the initial inspection limit.
"""
data = monthly_data.copy()
data["plan"] = data["cum_lot"].apply(
lambda x: "I" if x <= INITIAL_LIMIT else "S"
)
return data
狀態機推導 I / S / M
完成初始狀態後,接著逐月推導每個 product + subcon 的抽樣狀態。
這一步是整個演算法的核心。因為當期狀態不是只看當月資料,而是由歷史狀態與前幾期檢測結果共同決定。
狀態轉移規則可以簡化成三個條件:
- 只要當月發生 fail,狀態回到
S - 如果前 3 期皆為
S,且都有檢測資料、沒有 fail,則轉為M - 如果前一期已經是
M,且當月沒有 fail,則維持M
也就是說,M 是較寬鬆的減量檢測狀態,必須建立在連續穩定的歷史紀錄上;一旦發生 fail,就會回到較保守的 S。
這段程式會逐月覆寫狀態。前面已經先用累積 lot 數建立初始的 I / S 狀態,而這裡則根據每個月的檢測結果進一步推導是否可以進入 M。
其中 prev_3_lot、prev_3_fail、prev_3_plan 是滑動視窗概念,用來檢查前 3 個月是否符合穩定條件。
因此這段邏輯可以理解成:
先用累積 lot 數決定基礎狀態,再用最近 3 期紀錄判斷是否能進入減量檢測。
def mark_ism_status(data):
"""
Derive I / S / M inspection status month by month.
Rules:
- If the current month has any fail, set status to S.
- If the previous 3 months are all S, have lot data, and have no fail,
set status to M.
- If the previous month is M and the current month has no fail,
keep status as M.
"""
data = data.sort_values("cal_month").reset_index(drop=True).copy()
for i in range(3, len(data)):
current_fail = data.loc[i, "fail_or_not"]
previous_plan = data.loc[i - 1, "plan"]
prev_3_lot = data.loc[i - 3:i - 1, "lot_num"]
prev_3_fail = data.loc[i - 3:i - 1, "fail_or_not"]
prev_3_plan = data.loc[i - 3:i - 1, "plan"]
if current_fail > 0:
data.loc[i, "plan"] = "S"
elif (
(prev_3_lot > 0).all()
and (prev_3_fail == 0).all()
and (prev_3_plan == "S").all()
):
data.loc[i, "plan"] = "M"
elif current_fail == 0 and previous_plan == "M":
data.loc[i, "plan"] = "M"
return data
逐一套用到每個 product + subcon
前面的狀態推導只針對單一 product + subcon 時間序列。
實際資料中,同一個產品可能對應多個供應商,因此需要依照 prod_subcon 分組,逐一套用狀態機邏輯。
另外, 因為 I 是產品層級的初期狀態,不只是供應商層級,所以只要同一個產品在同一月份仍有任一供應商處於 I,該產品當月所有供應商都會維持 I。
這裡使用 groupby("prod_subcon"),讓每一組 product + subcon 都按照自己的歷史資料,獨立推導狀態。
但最後又額外做了一次 product-level 的同步判斷:只要同一個產品在同一月份仍有任一供應商被判定為 I,就把該產品該月的所有供應商都同步設為 I。
這樣可以避免同一個產品在初期觀察階段出現供應商之間狀態不一致的問題。
def apply_ism_status(monthly_data):
"""
Apply I / S / M status rules to each product-subcon time series.
Extra rule:
- If any subcon of the same product is still in I for a given month,
all subcon records of that product-month are kept as I.
"""
result = (
monthly_data
.groupby("prod_subcon", group_keys=False)
.apply(mark_ism_status)
.reset_index(drop=True)
)
has_initial_plan = (
result
.groupby(["prod_no", "cal_month"])["plan"]
.transform(lambda x: "I" in x.values)
)
result.loc[has_initial_plan, "plan"] = "I"
return result
預測下一期抽樣計畫
完成歷史月份的 I / S / M 狀態推導後,最後,根據每個 product + subcon 的最新狀態,產生下一期的抽樣計畫。
預測邏輯會取最近 3 期資料作為判斷依據:
- 如果最新狀態是
M,且最新一期沒有 fail,下一期維持M - 如果最新狀態是
M,但最新一期有 fail,下一期回到S - 如果最近 3 期都是
S,且都有檢測資料、沒有 fail,下一期轉為M - 其他情況則維持較保守的
S
這段程式的重點是只保留每個 product + subcon 最近 3 期資料。
因為下一期抽樣計畫不是重新計算全部歷史,而是根據目前最新狀態與最近幾期紀錄做決策。
如果目前已經是 M,代表該產品與供應商已經進入減量檢測狀態;只要最新一期沒有 fail,就可以延續 M。但只要發生 fail,就必須回到較保守的 S。
如果目前不是 M,則會檢查最近 3 期是否都符合穩定條件:皆為 S、皆有檢測資料、且皆無 fail。只有在這三個條件同時成立時,下一期才允許轉為 M。
此處使用 tail(3) ,主要是利用 Pandas 內部對 Index 的排序優化,直接定位到每個分組的末端記憶體位址,並取出最後三個單位。相較於手動 Slicing 或者是寫 list[-3:] ,這樣速度更快。
def predict_next_plan(plan_data):
"""
Predict the next inspection plan based on the latest status.
Rules:
- If the latest status is M and there is no fail, keep M.
- If the latest status is M but there is a fail, return to S.
- If the latest 3 months are all S, have lot data, and have no fail,
move to M.
- Otherwise, keep S.
"""
recent_data = (
plan_data
.groupby(["prod_subcon", "prod_no", "subcon_id"], group_keys=False)
.apply(lambda x: x.sort_values("cal_month").tail(3))
.reset_index(drop=True)
)
results = []
for prod_subcon, group in recent_data.groupby("prod_subcon"):
group = group.sort_values("cal_month")
next_row = group.iloc[-1].copy()
latest_plan = group["plan"].iloc[-1]
latest_fail = group["fail_or_not"].iloc[-1]
if latest_plan == "M":
next_row["plan"] = "M" if latest_fail == 0 else "S"
elif (
len(group) == 3
and (group["plan"] == "S").all()
and (group["fail_or_not"] == 0).all()
and (group["lot_num"] > 0).all()
):
next_row["plan"] = "M"
else:
next_row["plan"] = "S"
results.append(next_row)
return pd.DataFrame(results)到這一步,演算法就完成了從歷史資料到下一期抽樣計畫的推導:
先用歷史 lot 資料建立每月狀態,再根據最新狀態與最近 3 期紀錄,
產生下一期的 sample plan。
這樣設計的好處是, 抽樣策略不是單純看單月結果,而是同時考慮累積 lot 數、連續穩定性與 fail 事件,讓檢測標準能在效率與風險控管之間取得平衡。
心得:日期計算與滑動視窗
這次專案中,我覺得最有趣的部分是日期計算。
一開始我以為月報只是單純抓取當月資料,但實際做下去才發現,報表週期並不是自然月,而是以上月 19 號到本月 18 號作為一個完整計算區間。也就是說,程式不能只看月份本身,還必須根據日期判斷這筆資料應該被歸到哪一個報告月份。
例如 4 月報表實際上使用的是 3/19~4/18 的資料,讓我發現,資料分析中的日期格式轉換,要先理解業務規則,再把規則轉換成穩定的程式邏輯。
超有趣!使用除法計算日期位移
在這段實作中,我撰寫 _add_months() 這個函式來處理月份位移,避免直接對月份做加減時遇到跨年問題。例如 12 月往後推一個月會變成隔年 1 月,如果只用 month + 1,就很容易產生錯誤。因此我先把年份與月份轉成一個連續的月份 index,再用 divmod() 轉回正確的 year 和 month。
這個寫法讓我覺得很有收穫,因為我使用除法,把「日期邊界問題」轉換成比較穩定的數學問題。相同的概念,也可以應用在地理座標或chip座標的轉換上。
THRESHOLD_DAY = 18
def _add_months(year: int, month: int, delta: int) -> Tuple[int, int]:
"""
Shift (year, month) by delta months.
Steps:
1. Convert to absolute month index: year*12 + (month-1)
(month-1 makes it 0-based: Jan=0, ..., Dec=11)
2. Add delta to shift months.
3. Use divmod(..., 12) to get back (year, month0).
4. Convert month0 back to 1–12 by adding 1.
"""
total = year * 12 + (month - 1) + delta
new_year, new_month0 = divmod(total, 12)
return new_year, new_month0 + 1
def _reporting_month(now: datetime | None = None, threshold_day: int = THRESHOLD_DAY) -> Tuple[int, int]:
"""
Get the reporting base month based on threshold_day:
- If today < threshold_day -> use the previous month
- Otherwise -> use the current month
Returns (year, month).
"""
now = now or datetime.now()
base_delta = -1 if now.day < threshold_day else 0
return _add_months(now.year, now.month, base_delta)
除了日期計算之外,另一個收穫是實際練習了滑動視窗的概念。
在判斷抽樣狀態時,不能只看單一月份的結果,而是要看最近幾期是否連續穩定。
例如要從 S 轉成 M,就必須確認前 3 期都有檢測資料、沒有 fail,且狀態都符合條件。 這其實就是一種 sliding window 的應用:每次往後推一個月份,就重新檢查最近 3 期的資料是否符合轉換條件。
過去我練習演算法時,滑動視窗通常出現在 LeetCode 題目中,例如找連續子陣列、最大值或符合條件的區間。但這次專案讓我看到,滑動視窗不只是刷題技巧,也可以用在真實的製造資料分析中,幫助系統根據連續月份的結果做決策。
這次實作讓我最大的感受是:演算法不一定是很複雜的模型,把業務規則拆解清楚,再選擇合適的資料結構與判斷邏輯,其實解決複雜現實實務的祕密,就藏在讀過的書或者練習過的題目裡。
日期計算解決了資料的日期,滑動視窗解決了狀態改變問題。當這兩個問題被處理好,後續的 I / S / M 狀態推導就可以持續穩定了。





